在電腦裡搞一個 RWKV AI 小助手
Hi 大家好,我是 Johnny。最近有感於 AI 技術不斷蓬勃發展,想說來研究一下時下最新的 AI 技術資訊,當然最知名的除了為人所熟知的微軟 OpenAI ChatGPT之外,大概就是 Facebook Meta 的 Llama 了吧
但上述兩個都已經被各位大佬講到爛掉了,沒有小弟我的發言權Q_Q,今天這篇要來以一位 AI 菜鳥的角度,學習、介紹一款相對比較沒有被大家討論的技術叫做「RWKV」(Receptance Weighted Key Value)
什麼是 RWKV?(Receptance Weighted Key Value)
是由 Peng Bo 受 AFT(Attention-Free Transformer)等語言模型啟發,設計並進一步開發的大型語言模型(Large Language Model)
- RWKV 是一種具有 Transformer 級 LLM 性能的 RNN。
- 可以像 GPT(可並行化)一樣直接訓練。結合了 RNN 和 Transformer 的優點,同時解決傳統 RNN 的缺陷(梯度消失、爆炸)
- 出色的性能、快速推理、節省 VRAM、快速訓練、「無限」ctx_len 和免費句子嵌入。
AFT 是 Apple 公司提出的一種新型的神經網路模型,減少 transformer 的計算量、提升性能
設計架構
本質上來說,RWKV 跟 GPT 完全不一樣,R-Transformer 是針對高維嵌入導致位置編碼失效的一種解決方案,而 RWKV 則改造 AFT,採用 Linear Transformer 算法,使用 WKV 計算取代 Self-Attension 的部分進行優化,詳細說明可參考這篇,實作可以看這邊RWKV_in_150_lines.py
最終針對 token 的計算,在不考慮 embedding 維度的情況下,計算複雜度從 O(n^2) 壓縮到 O(n),也因此更節省 VRAM 且快速
Transformer 核心是 self-attention 機制,整句並行化處理,訓練效率高、計算複雜度高,但會有 Position Embedding 問題(詞序遺失)
R-Transformer 則是透過單個 RNN 捕捉位置來代替 Position Embedding,解決傳統 RNN 問題的同時也能並行化處理,但同樣計算複雜度高


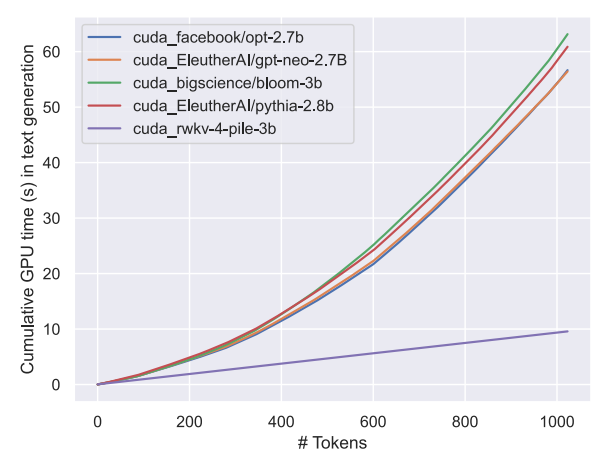
性能對比
RWKV 模型,時間消耗隨序列長度呈現線性增加,時間消耗遠小於其他各種 Transformer
實際下載玩玩
相信有在本機環境中,實際跑過 Llama model 的人一定都知道,其對於中文語意的理解能力實在不敢恭維,必須另外安裝中文訓練的擴充才能更好地以中文回答問題,且本機跑的速度非常緩慢,常常跑一跑就整個卡住
那使用 RWKV 呢?
下載
筆者以 MacOS M1 環境示範,不同環境的安裝教學請參考官方文件
$ git clone https://github.com/RWKV/rwkv.cpp
$ cd rwkv.cpp
安裝
$ brew install cmake
$ cmake .
$ cmake --build . --config Release
Mac M1 晶片執行完
cmake .後需注意CMAKE_SYSTEM_PROCESSOR: arm64,如果偵測結果是x86_64,需要手動在CMakeLists.txt檔案裡,找到# Compile flags,並加入set(CMAKE_SYSTEM_PROCESSOR "arm64")
完成後會看到 librwkv.so (Linux) 或 librwkv.dylib (MacOS) 在資料夾中
取得 RWKV model
可以去 Hugging Face 下載,這裡提供一個簡單的範例 BlinkDL/rwkv-4-pile-1b5
轉換為 rwkv.cpp 格式
轉換之前,先安裝 python 的依賴(以下都是使用 python3)
$ pip install torch numpy tokenizer
轉換成 ggml - FP16
$ python python/convert_pytorch_to_ggml.py ~/Downloads/RWKV-4-Pile-1B5-20220929-ctx4096.pth ~/Downloads/rwkv.cpp-4pile-1b5.bin FP16
quantize 成 Q5_1 或是其他你想要的格式(差別在解析準確度跟速度)
$ python python/quantize.py ~/Downloads/rwkv.cpp-4pile-1b5.bin ~/Downloads/rwkv.cpp-4pile-1b5-Q5_1.bin Q5_1
執行 Chat with BOT
接下來就是見證奇蹟的時刻!!輸入下面指令,啟動指定的 model 後,就可以在 Terminal 中與它交談了
$ python python/chat_with_bot.py ~/Downloads/rwkv.cpp-4pile-1b5-Q5_1.bin
個人在本機實測,MacOS M1 VRAM 16G 跑 3B 的 model 還蠻順暢的,但 7B 的就會卡頓,使用時要特別注意,不要害電腦 CPU 燒掉就尷尬了
結論
實際下載玩一次之後,發現比 Llama 還容易上手,而且對於中文的理解能力更準確,即使是 1B5 的 model 也還是具有一定的應答能力,相比於同規格的 Llama model,反應力與回答準確率是高出不少,個人蠻期待這個技術後續的發展,我自己還動手把他的 chat_with_bot.py 改寫成了 API,拿來做成一些小服務,變成我的玩具迷你 ai 助手了 XDDD
雖然 RWKV 模型號稱地表上「最環保的模型」,但畢竟生態系、算法加速 library 生態規模與 Transformer 差距非常大,未來能不能發展成主流還要需要再觀察
今天就分享到這拉,希望大家會喜歡,我們下篇文章見~=V=